
If you're an AI application developer working with agents, tool calling, and complex multi-step workflows, this comparison cuts through the marketing noise. We'll examine real benchmarks, actual pricing, and—most importantly—how these models handle the kinds of tasks you're building with platforms like Klavis AI and the Model Context Protocol.
The State of Agentic AI
Let's be clear about what's changed. The gap between "chatbot that writes code" and "autonomous agent that ships features" has narrowed dramatically. Claude Opus 4.5 excels at long-horizon, autonomous tasks, especially those that require sustained reasoning and multi-step execution. Meanwhile, Gemini 3 is "the best vibe coding and agentic coding model we've ever built" according to Google. And GPT-5 is "better at agentic tasks generally", setting new records on benchmarks of instruction following (69.6% on Scale MultiChallenge) and tool calling (96.7% on τ2-bench telecom).
These aren't incremental improvements. We're talking about models that can autonomously work for 20-30 minutes without human intervention, manage context across thousands of tools, and actually ship production-quality code.
Benchmark Battle: Where Each Model Shines
SWE-bench Verified: The Gold Standard for Coding Agents
SWE-bench tests whether a model can solve real GitHub issues—the kind developers face daily. It's not about toy problems; it's about fixing actual bugs in production codebases.
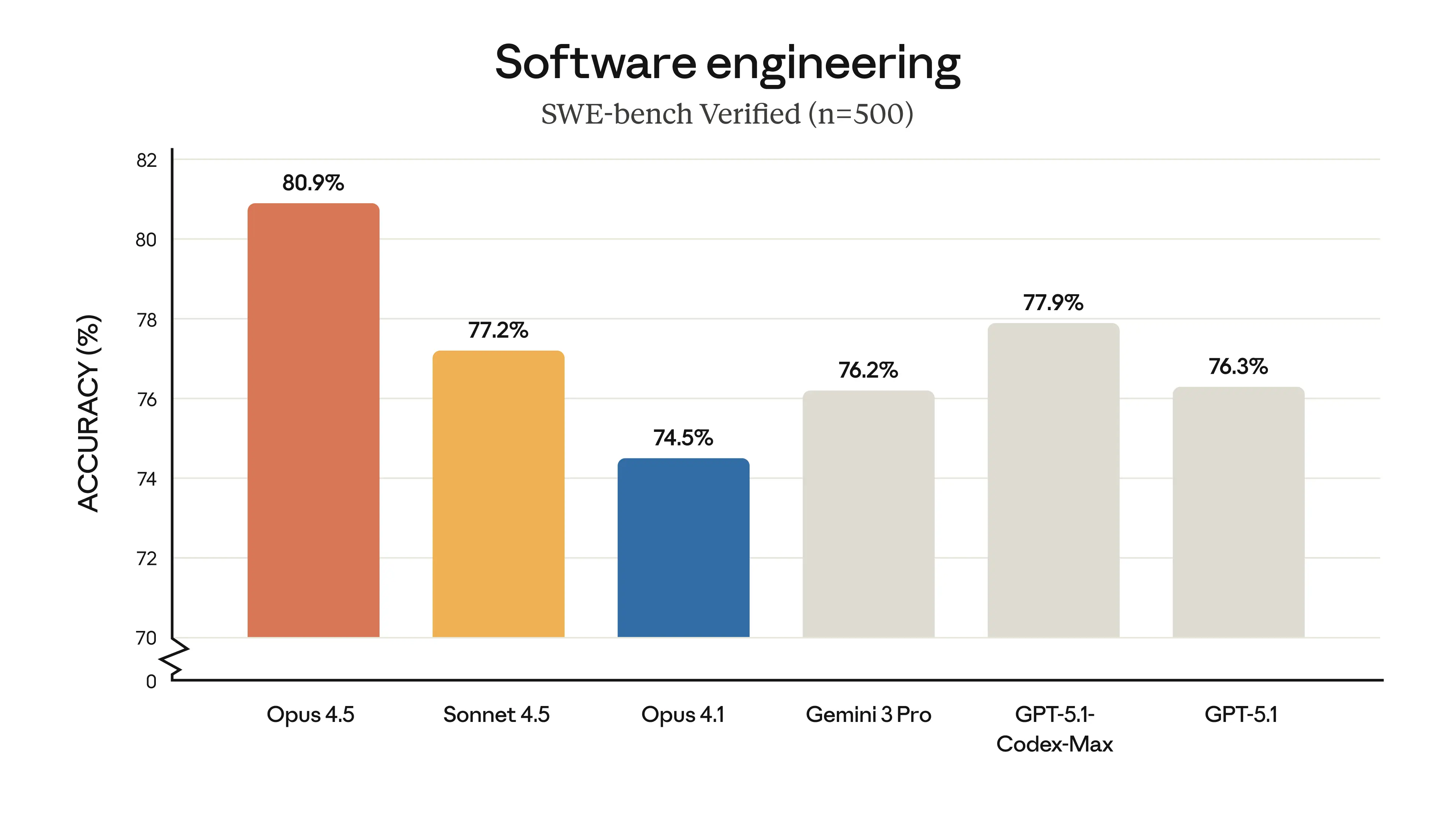
Claude Opus 4.5 takes the crown here, but context matters. At medium effort level, Opus 4.5 matches Sonnet 4.5's best score on SWE-bench Verified, but uses 76% fewer output tokens. That's not just performance—it's efficiency that compounds at scale.
Tool Calling: The Backbone of Agentic Systems
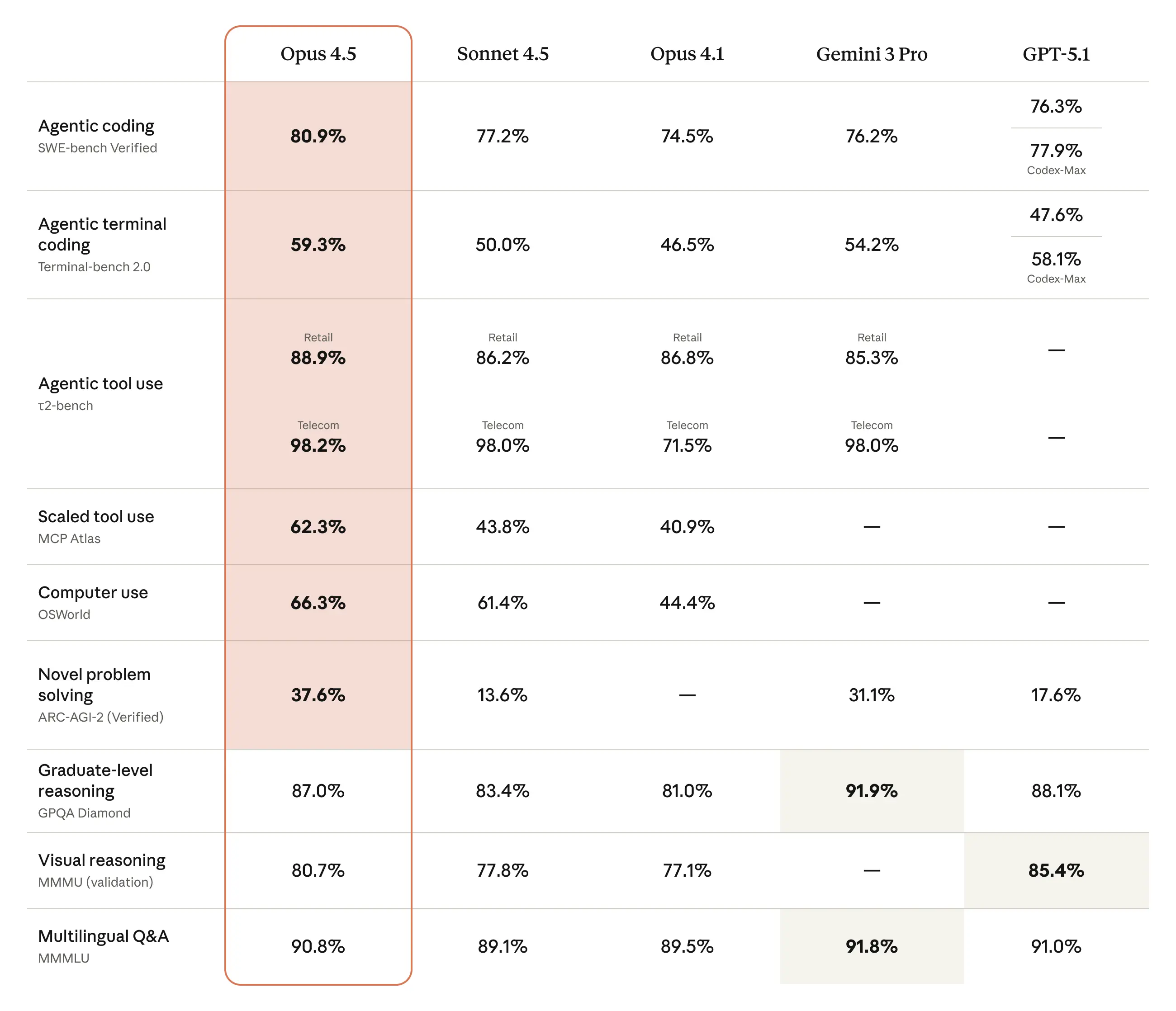
For developers building agents that need to interact with external APIs, databases, and services (hello, Klavis AI users), tool calling accuracy is non-negotiable.
Claude Opus 4.5 demonstrates exceptional tool orchestration capabilities. It exhibits "the best frontier task planning and tool calling we've seen yet," according to Windsurf CEO Jeff Wang. The model shows 50% to 75% reductions in both tool calling errors and build/lint errors compared to previous versions.
GPT-5 scores 97% on τ2-bench telecom—a benchmark where no model scored above 49% just two months prior. The model excels at reliably chaining together dozens of tool calls—both in sequence and in parallel—without losing its way.
Gemini 3 Pro scores Terminal-Bench 2.0 with 54.2%, which tests a model's tool use ability to operate a computer via terminal. Its strength lies in advanced tool use and planning, facilitating long-running tasks across enterprise systems and data.
Multi-Agent Coordination: The Next Frontier
Here's where things get interesting for complex workflows:
- Claude Opus 4.5: 92.3% on multi-agent search benchmark versus Sonnet 4.5's 85.4%, with gains at both orchestration and execution levels
- Gemini 3 Pro: Achieved a 10% boost in relevancy for complex code-generation tasks and noted a 30% reduction in tool-calling mistakes at Geotab
- GPT-5: Comparable to or better than experts in roughly half the cases across tasks spanning over 40 occupations
The Real-World Test: What Developers Are Saying
Benchmarks tell part of the story. Here's what actually matters:
Claude Opus 4.5 in Production
"With Opus 4.5, autonomous work sessions routinely stretch to 20 or 30 minutes. When I come back, the task is often done—simply and idiomatically," reports Adam Wolff. The model's self-improving AI agents can autonomously refine their own capabilities—achieving peak performance in 4 iterations while other models couldn't match that quality after 10.
For Klavis AI users integrating MCP servers at scale, this means fewer intervention points and more reliable execution across your tool ecosystem.
Gemini 3 Pro's Strengths
Google's model excels at "vibe coding," topping the WebDev Arena leaderboard with an impressive 1487 Elo. The model demonstrated 35% higher accuracy in resolving software engineering challenges than Gemini 2.5 Pro in GitHub Copilot testing. For rapid prototyping and front-end development, Gemini 3 Pro is a powerhouse.
GPT-5's Unified Approach
GPT-5 is OpenAI's first "unified" AI model and combines the reasoning abilities of its o-series of models with the fast responses of its GPT series. This router-based architecture means GPT-5 can feel both fast and deeply capable—delivering expert-level answers where needed, while still handling everyday queries with speed and grace.
Pricing: The Real Cost of Intelligence
When you're running thousands of API calls daily, pricing isn't academic—it's your burn rate.
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Context Window |
|---|---|---|---|
| Claude Opus 4.5 | $5 | $25 | 200K |
| Gemini 3 Pro | $2 (or $4 >200K) | $12 (or $18 >200K) | 1M |
| GPT-5 | $1.25 | $10 | 400K |
GPT-5 wins on raw pricing, but remember Claude Opus 4.5's token efficiency. At medium effort level, Opus 4.5 matches Sonnet 4.5's peak performance while consuming 76% fewer output tokens. Even at high effort—it uses approximately half the tokens of the previous model.
For organizations running agentic workflows through Klavis AI's MCP infrastructure, these efficiency gains can translate to 50-75% cost reductions at scale while maintaining or improving output quality.
Tool Calling Deep Dive: What Matters for MCP Integration
If you're building with the Model Context Protocol, here's what you need to know:
Parallel Tool Execution
Claude Sonnet 4.5 more effectively uses parallel tool calls, firing off multiple speculative searches simultaneously and reading several files at once to build context faster. Opus 4.5 extends this capability with improved coordination. GPT-5 is better at proactively making many tool calls in sequence or in parallel, which is critical when your agents need to orchestrate across dozens of MCP servers simultaneously.
Context Management for Long-Running Agents
Gemini 3 Pro's 1M token context window provides raw capacity, but effective memory management matters more than window size. As Anthropic's head of product management explains, "Context windows are not going to be sufficient by themselves. Knowing the right details to remember is really important."
Claude Opus 4.5's compaction control helps handle long-running agentic tasks more effectively with new SDK helpers that manage context efficiently over extended interactions.
Progressive Tool Discovery with Klavis AI
Here's where things get practical. When you're working with lots of MCP servers, overwhelming your agent with hundreds of tools simultaneously kills performance.
This is exactly the problem Klavis AI's Strata solves. Instead of presenting all tools at once, Strata implements progressive discovery:
- Intent Recognition: AI identifies high-level user intent
- Category Navigation: Guides to relevant tool categories
- Action Selection: Drills down to specific actions
- API Execution: Reveals details only when needed
Claude Sonnet 4.5 maintains focus for more than 30 hours on complex, multi-step tasks. Combined with Strata's progressive approach, you get agents that can work autonomously across your entire tool ecosystem without context pollution.
Practical Recommendations for AI Developers
After analyzing benchmarks, pricing, and real-world usage, here's how to choose:
Choose Claude Opus 4.5 If:
- You're building production agents that need multi-hour autonomous operation
- Token efficiency matters more than raw input costs
- You need the highest tool calling accuracy (50-75% error reduction)
- Your workflows involve complex, multi-step reasoning across many tools
- You're integrating with Klavis AI's MCP infrastructure for enterprise deployments
Perfect for: Complex agentic workflows, code migration projects, multi-agent orchestration
Choose Gemini 3 Pro If:
- Front-end development and "vibe coding" are priorities
- You need massive context windows (1M tokens) for codebase analysis
- Cost optimization is critical ($2/$12 pricing)
- Multimodal reasoning (video, images) is important
- You're prototyping rapidly and need fast iteration
Perfect for: Rapid prototyping, web development, creative coding, visual applications
Choose GPT-5 If:
- You need the lowest cost per token at scale ($1.25/$10)
- Hybrid reasoning (fast + deep thinking) fits your use case
- You want unified reasoning + fast response in one model
- Integration with Microsoft ecosystem is important
- You need the highest τ2-bench scores (97%) for telecom-style workflows
Perfect for: High-volume applications, conversational agents, cost-sensitive deployments
Real-World Example: Building an MCP-Powered Agent
Let's make this concrete. Say you're building an agent that needs to:
- Query a GitHub repository
- Search relevant documentation
- Create a Jira ticket
- Update a Notion database
- Send a Slack notification
With Klavis AI, you'd configure these MCP servers:
from klavis import Klavis
klavis = Klavis(api_key="your-key")
strata = klavis.mcp_server.create_strata_server(
user_id="developer_001",
servers=[
McpServerName.GITHUB,
McpServerName.JIRA,
McpServerName.NOTION,
McpServerName.SLACK
]
)
With Claude Opus 4.5: The agent would exhibit "the best frontier task planning and tool calling," making fewer errors and completing the workflow in fewer iterations. Cost: ~$25-35 per 1M output tokens, but you'd use 50-75% fewer tokens.
With Gemini 3 Pro: Fast execution and good tool coordination at 30% fewer tool-calling mistakes compared to previous versions. Cost: $12-18 per 1M output tokens.
With GPT-5: Reliably chains together dozens of tool calls in sequence and parallel with industry-leading τ2-bench scores. Cost: $10 per 1M output tokens.
For more details, checkout Klavis AI documentation on building MCP-powered agents.
The Klavis AI Advantage
What makes these models truly powerful isn't just their raw capability—it's how you architect your tool infrastructure. Klavis AI provides:
- 100+ Production-Ready MCP Servers with enterprise OAuth
- Strata's Progressive Discovery preventing tool overload
- Built-in Multi-tenancy for secure, scalable deployments
- Unified API working seamlessly with all three frontier models
Performance comparisons show Strata's approach delivers:
- +13.4% higher pass@1 rate vs official Notion MCP
- +15.2% higher pass@1 rate vs official GitHub MCP
- 83%+ accuracy on complex multi-app workflows
When you combine Claude Opus 4.5's tool calling precision, Gemini 3 Pro's speed, or GPT-5's cost efficiency with Klavis AI's infrastructure, you're not just building agents—you're shipping reliable, production-grade AI systems.
FAQ: What Developers Really Want to Know
Q: Which model should I use for my AI agent startup?
Start with GPT-5 for cost efficiency during development. Once you've validated product-market fit and need maximum reliability, migrate to Claude Opus 4.5 for production workflows where token efficiency and reduced errors matter.
Q: Can I switch between models dynamically?
Yes. Klavis AI's infrastructure supports all three models through a unified API. You can route simpler queries to GPT-5 or Gemini 3 Pro for cost savings, and complex multi-step workflows to Claude Opus 4.5 for reliability.
Q: How does Model Context Protocol fit into this?
MCP is the standard that makes these models actually useful for production work. Instead of building custom integrations for every tool, MCP provides a universal protocol. Klavis AI's 50+ pre-built MCP servers mean you can connect any of these models to GitHub, Slack, Notion, databases, and cloud services instantly—with built-in OAuth and security.
Q: What about context window limits?
Gemini 3 Pro's 1M token window wins on paper, but effective context management matters more. Claude Opus 4.5's compaction control and GPT-5's router-based approach often perform better in practice by intelligently managing what to remember vs. what to discard.