
If you're building AI applications in 2025, here's a question you've probably asked yourself: Which model should I use for function calling? The answer isn't simple, and traditional benchmarks like MMLU or HumanEval won't help much. A model that scores 90% on a math test might completely fail when asked to chain three API calls, manage context across a 10-turn conversation, or—crucially—know when not to use a tool.
That's where function calling benchmarks come in, and they're finally painting a realistic picture of what these models can actually do in production.
1. The Berkeley Function Calling Leaderboard
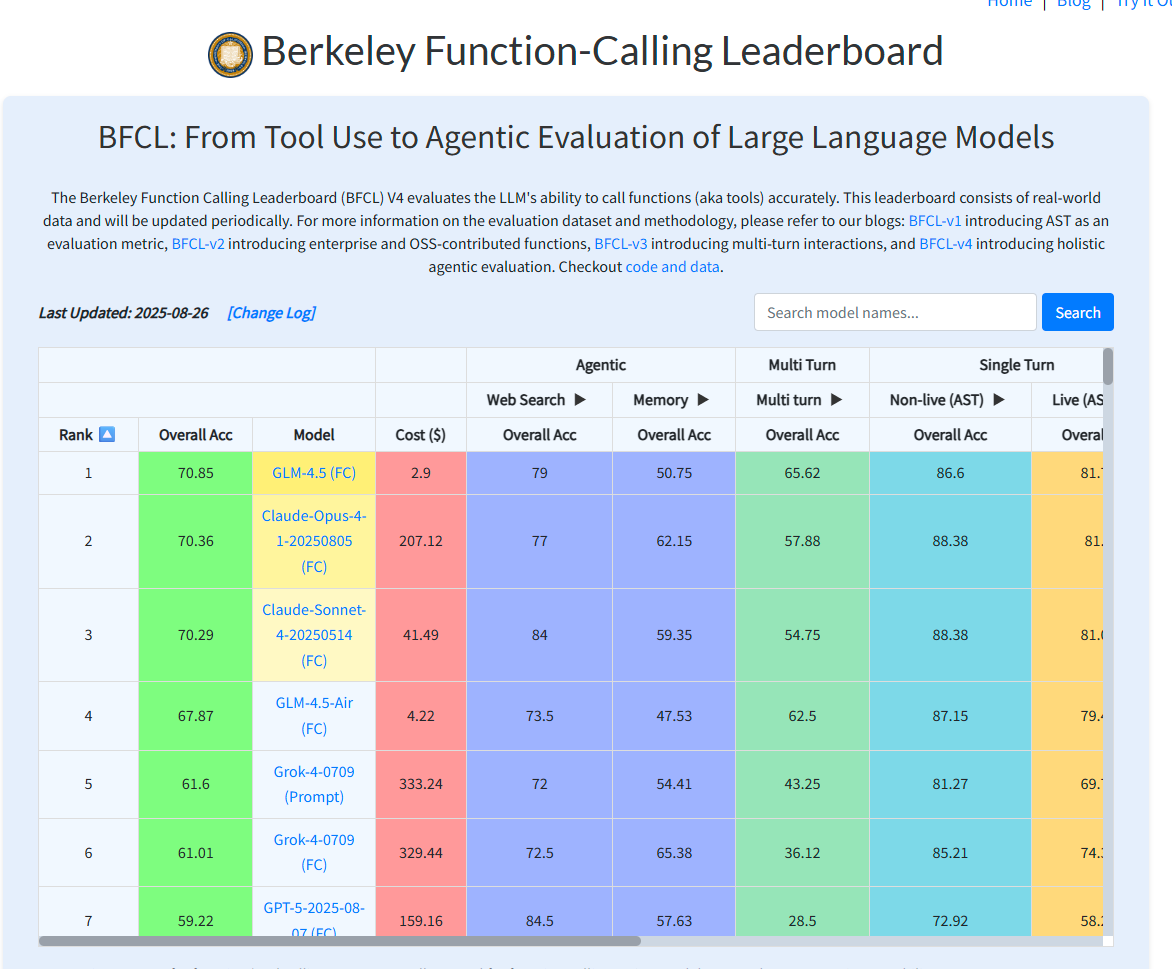
The Berkeley Function Calling Leaderboard (BFCL) has emerged as the defacto standard for evaluating function-calls. Developed by UC Berkeley researchers, BFCL was the first comprehensive benchmark designed to evaluate function calling capabilities across real-world settings.
What Makes BFCL Different?
BFCL stands out because of its comprehensive evaluation methodology. It consists of 2k question-function-answer pairs with multiple languages (python, java, javascript, restAPI), diverse application domains and complex use cases.
The benchmark tests models across several critical dimensions:
| Test Category | What It Measures | Why It Matters |
|---|---|---|
| Simple Function Calling | Single function invocation from description | Baseline competency for tool use |
| Parallel Function Calling | Multiple simultaneous function calls | Tests ability to batch operations efficiently |
| Multiple Function Selection | Choosing correct tool(s) from many options | Evaluates decision-making under choice overload |
| Relevance Detection | Knowing when NOT to call functions | Critical for preventing hallucinated actions |
| Multi-turn Interactions | Sustained conversations with context | Tests memory and long-horizon planning |
| Multi-step Reasoning | Sequential function calls where outputs feed inputs | Evaluates complex workflow orchestration |
The BFCL benchmark evaluates serial and parallel function calls, across various programming languages using a novel Abstract Syntax Tree (AST) evaluation method that can easily scale to thousands of functions.
Current BFCL Performance: The State of Play
The latest BFCL results reveal fascinating patterns in model performance:
Top Performers (as of Oct 2025):
- GLM-4.5 (FC): 70.85%
- Claude Opus 4.1: 70.36%
- Claude Sonnet 4: 70.29%
- GPT-5: 59.22%
Early results reveal a split personality: top AIs ace the one-shot questions but still stumble when they must remember context, manage long conversations, or decide when not to act.
Performance Breakdown by Model Type
Let's look at how different model families perform:
OpenAI's Models: GPT-5 scores 59.22% on the BFCL benchmark, placing it 7th overall. While this is lower than the top Chinese and Anthropic models in function calling benchmarks, GPT-5 excels in multimodal tasks and maintains strong versatility across domains, particularly in complex agentic workflows.
Anthropic's Claude: Claude Sonnet 4 ranks 3rd on the BFCL benchmark at 70.29%, while Claude Opus 4.1 ranks 2nd at 70.36%. Both models demonstrate strong performance in function calling, with Claude consistently showing strength in structured output generation and following complex schemas.
2. MCPMark: Stress-Testing Real-World MCP Use
While BFCL evaluates function calling in controlled environments, MCPMark takes things to the next level by testing models on realistic, comprehensive Model Context Protocol (MCP) use. MCPMark consists of 127 high-quality tasks collaboratively created by domain experts and AI agents.
Why MCPMark Represents the Cutting Edge
These tasks demand richer and more diverse interactions with the environment, involving a broad range of create, read, update, and delete (CRUD) operations. Unlike many benchmarks that focus on read-heavy operations, MCPMark evaluates the full spectrum of real-world actions.
MCPMark spans five representative MCP environments: Notion, GitHub, Filesystem, PostgreSQL and Playwright. Each task includes a curated initial state and programmatic verification script, ensuring reproducibility and rigor.
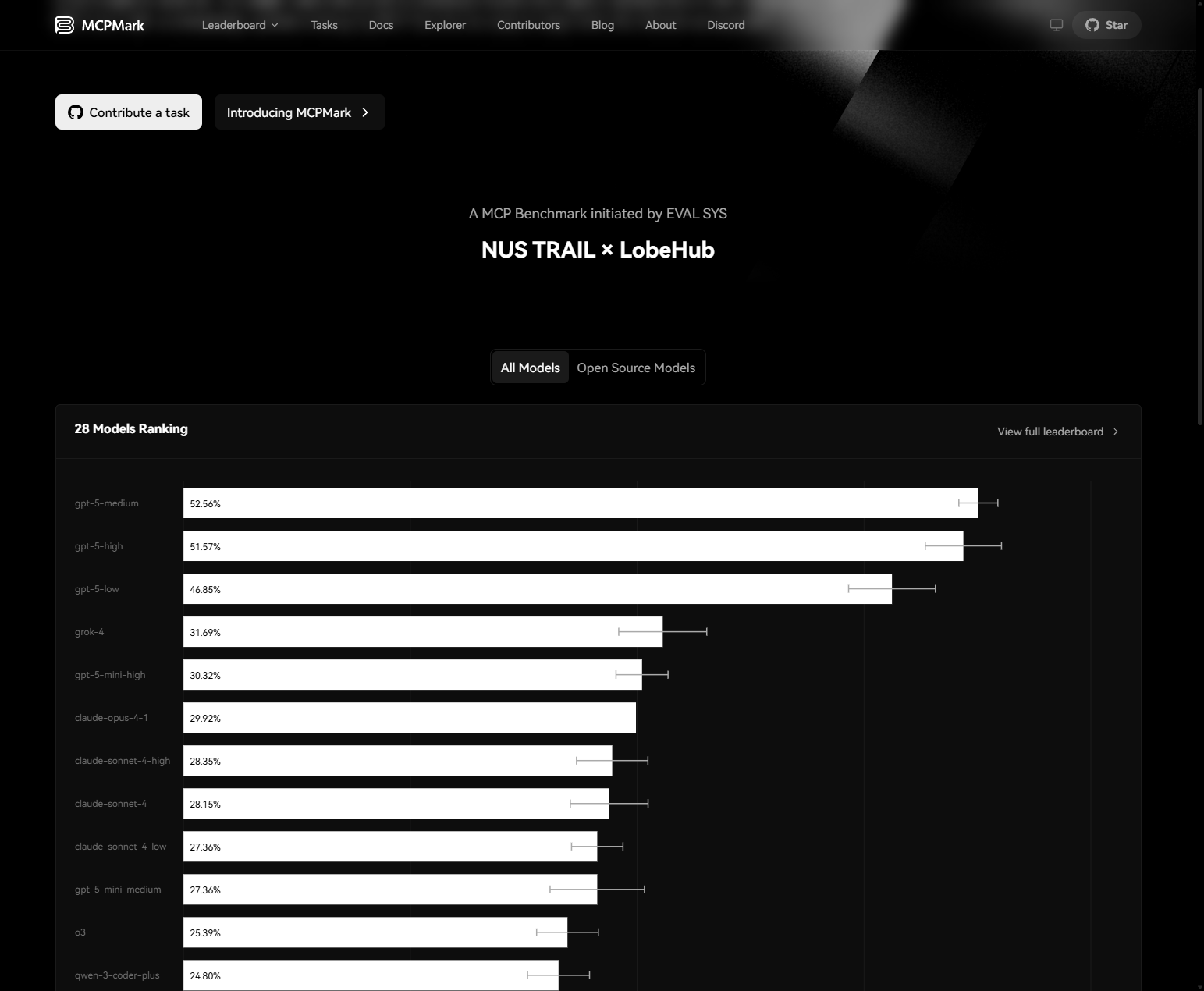
MCPMark Performance: Reality Check
The results from MCPMark are humbling. The best-performing model, gpt-5-medium, reaches only 52.6% pass@1 and 33.9% pass^4, while other widely regarded strong models, including claude-sonnet-4 and o3, fall below 30% pass@1 and 15% pass^4.
Let's break down what these metrics mean:
- pass@1: Success rate on the first attempt
- pass@4: Success rate within four attempts
- pass^4: Consistency metric (all four attempts succeed)
Here's the detailed performance breakdown:
| Model | Pass@1 | Pass@4 | Pass^4 | Avg Cost per Run | Avg Agent Time |
|---|---|---|---|---|---|
| GPT-5 Medium | 52.6% | 68.5% | 33.9% | $127.46 | 478.21s |
| Claude Sonnet 4 | 28.1% | 44.9% | 12.6% | $252.41 | 218.27s |
| Claude Opus 4.1 | 29.9% | - | - | $1,165.45 | 361.81s |
| o3 | 25.4% | 43.3% | 12.6% | $113.94 | 169.42s |
| Qwen-3-Coder | 24.8% | 40.9% | 12.6% | $36.46 | 274.29s |
GPT-5 shows the most impressive performance, clearly ahead of the others. Claude is strong across every MCP and ranks just behind GPT-5 overall.
The Complexity Factor
On average, LLMs require 16.2 execution turns and 17.4 tool calls per task, significantly surpassing those in previous MCP benchmarks and highlighting the stress-testing nature of MCPMark. This is dramatically different from simple "book a meeting" function calling scenarios.
Consider this: a typical MCPMark task might require:
- Reading current state from a Notion database
- Processing that data through multiple transformations
- Making decisions based on constraints
- Updating records across multiple systems
- Verifying the changes meet specifications
Each step depends on the previous one. One mistake cascades through the entire workflow.
Model-by-Model Deep Dive: Who Excels Where?
GPT-5: The Cost-Effective Generalist
MCPMark Results:  Berkeley Berkeley Function Calling Leaderboard Results:
Berkeley Berkeley Function Calling Leaderboard Results: 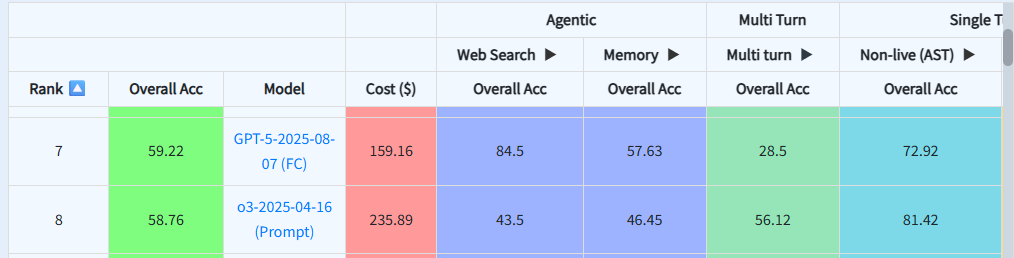
OpenAI's GPT-5 leads MCPMark performance while maintaining strong cost-effectiveness. At approximately $127.46 per benchmark run, it's significantly cheaper than Claude Sonnet 4 ($252.41) while delivering superior pass@1 rates.
Strengths:
- Best-in-class MCPMark performance (52.6% pass@1)
- Reasonable cost structure at $1.25/M input tokens, $10/M output tokens
- Average agent execution time (478.21 seconds)
- Strong multimodal capabilities
Limitations:
- Lower BFCL scores compared to specialized tool-use models
- Not the cheapest option for simple function calls
Best For: Production applications requiring reliable multi-step workflows where cost matters
Claude 4 Family: Premium Reasoning
MCPMark Results:  Berkeley Berkeley Function Calling Leaderboard Results:
Berkeley Berkeley Function Calling Leaderboard Results: 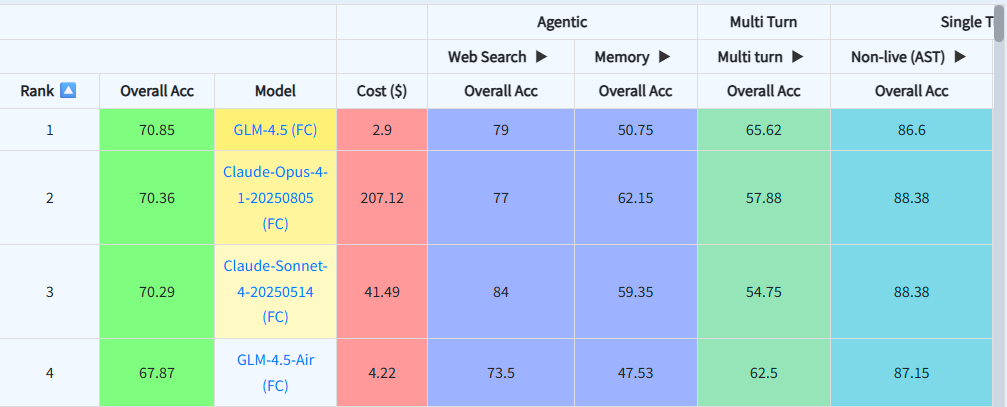
Anthropic's Claude 4 family—including Sonnet 4 and Opus 4.1—represents the premium tier for reasoning-intensive tasks.
Claude Sonnet 4:
- MCPMark: 28.1% pass@1, 44.9% pass@4, 12.6% pass^4
- Cost: $3/M input, $15/M output tokens
Claude Opus 4.1:
- "The best coding model in the world" according to Anthropic
- MCPMark: 29.9% pass@1
- Cost: $15/M input, $75/M output tokens
- Autonomously executed a task equivalent to playing Pokémon Red continuously for 24 hours
Strengths:
- Superior reasoning on complex, multi-step problems
- Best-in-class code generation quality
- Strong safety and alignment features
- Excellent for long-running agentic workflows
Limitations:
- Significantly higher cost per task
- Slower execution times (218.27s average for Sonnet 4, 361.81s for Opus 4.1)
- Lower pass@1 rates on MCPMark despite high quality when successful
Best For: Enterprise applications where code quality and reasoning depth justify premium pricing
Gemini 2.5: The Multimodal Powerhouse
MCPMark Results:  Berkeley Berkeley Function Calling Leaderboard Results:
Berkeley Berkeley Function Calling Leaderboard Results: 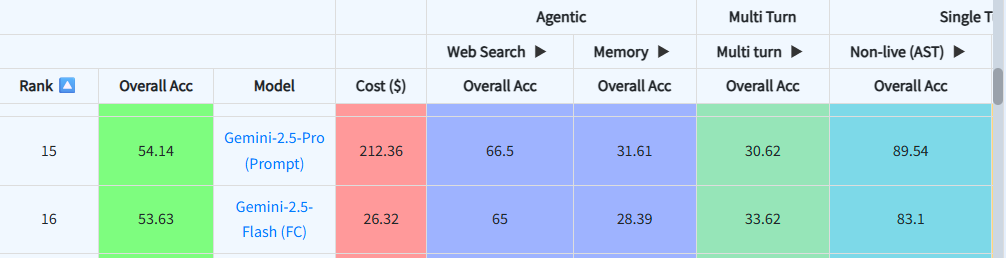
Google's Gemini family emphasizes native tool use and agentic capabilities.
Gemini 2.5 Pro:
- Tops the LMArena leaderboard by significant margin
- Native integration with Google Search, code execution
Strengths:
- Native tool calling without prompt engineering
- Excellent multimodal understanding (text, image, audio, video)
- Strong agentic capabilities with Project Mariner
Limitations:
- Limited third-party benchmarking on BFCL/MCPMark
- Primarily optimized for Google ecosystem tools
- Pricing varies by deployment method
Best For: Applications requiring multimodal reasoning and Google service integration
Qwen 3: The Efficient Alternative
MCPMark Results:  Berkeley Berkeley Function Calling Leaderboard Results:
Berkeley Berkeley Function Calling Leaderboard Results: 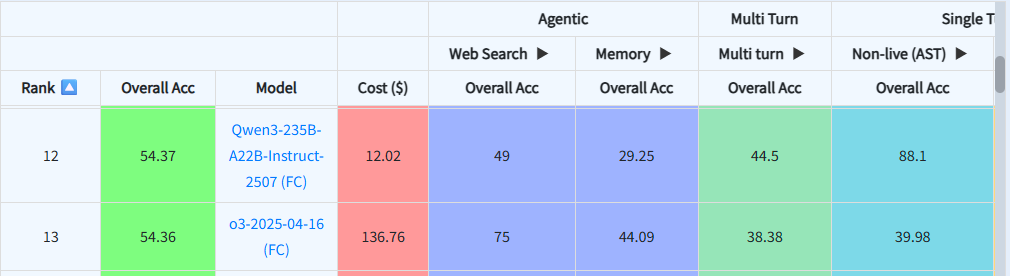
Alibaba's Qwen family has gained traction for strong performance in smaller packages.
Qwen-3-Coder:
- MCPMark: 24.8% pass@1 (competitive for open-source)
- Cost: $36.46 per MCPMark run (lowest among top performers)
- Average agent time: 274.29s
- Hermes-style tool use for maximized function calling performance
Strengths:
- Best cost efficiency among capable models
- Fast execution times
- Strong coding capabilities
- Native support for tool calling via Hermes-style
Limitations:
- Lower absolute performance compared to GPT-5/Claude
- Less extensive documentation than Western models
Best For: Budget-conscious development and rapid prototyping
The Cost-Performance Tradeoff
Here's something benchmarks often ignore but developers care about deeply: cost. When your agent makes 16+ function calls per task, pricing matters enormously.
Looking at MCPMark data, the cost variation is dramatic:
| Model | Cost per Benchmark Run | Pass@1 | Cost per Successful Task |
|---|---|---|---|
| Qwen-3-Coder | $36.46 | 24.8% | ~$147.02 |
| GPT-5 Medium | $127.46 | 52.6% | ~$242.40 |
| Claude Sonnet 4 | $252.41 | 28.1% | ~$897.90 |
Token usage and cost vary dramatically across models — some models burn way more tokens (and 💸) than others. This cost gap highlights the tradeoff between raw performance vs. efficiency.
For a production system processing thousands of user requests daily, this difference compounds quickly. A model that's 10% more accurate but 14x more expensive might not be the right choice for your use case.
Real-world calculation: If your application processes 10,000 agentic tasks per month:
- Qwen-3-Coder: ~$1,470,200/month (at 24.8% success, requiring ~4x attempts)
- GPT-5: ~$242,400/month (at 52.6% success, ~1.9x attempts for reliability)
- Claude Sonnet 4: ~$897,900/month (at 28.1% success, ~3.6x attempts)
The math changes the conversation entirely.
The Infrastructure Layer: Making It All Work
While benchmarks reveal what models can do, production deployment requires solving infrastructure challenges that benchmarks don't measure:
- Authentication: Managing OAuth flows across dozens of services
- Error handling: Recovering from transient failures
- Multi-tenancy: Isolating customer data and credentials
- Monitoring: Tracking success rates and costs
- Schema management: Keeping function definitions current
This is where infrastructure providers become relevant. Klavis AI provides production-ready MCP server integrations for services—from GitHub and Linear to Notion and Salesforce—with enterprise OAuth support and built-in security guardrails.
For teams building agentic applications, this infrastructure layer matters because:
- Function calling performance depends on reliable tool availability
- Authentication failures break multi-step workflows
- Rate limit handling prevents cascade failures
- Proper error handling improves agent resilience
The benchmark scores we've discussed assume perfect tool availability. In production, the infrastructure work often determines whether your agent actually achieves those benchmark-level results with real users.
Klavis AI: Proven Performance on MCPMark MCP Server Leaderboard
But infrastructure quality isn't just about convenience—it directly impacts performance. Klavis AI's Strata MCP Server has demonstrated this on the MCPMark MCP Server Leaderboard, where different MCP server implementations are tested using the same model baseline (Claude Sonnet 4).
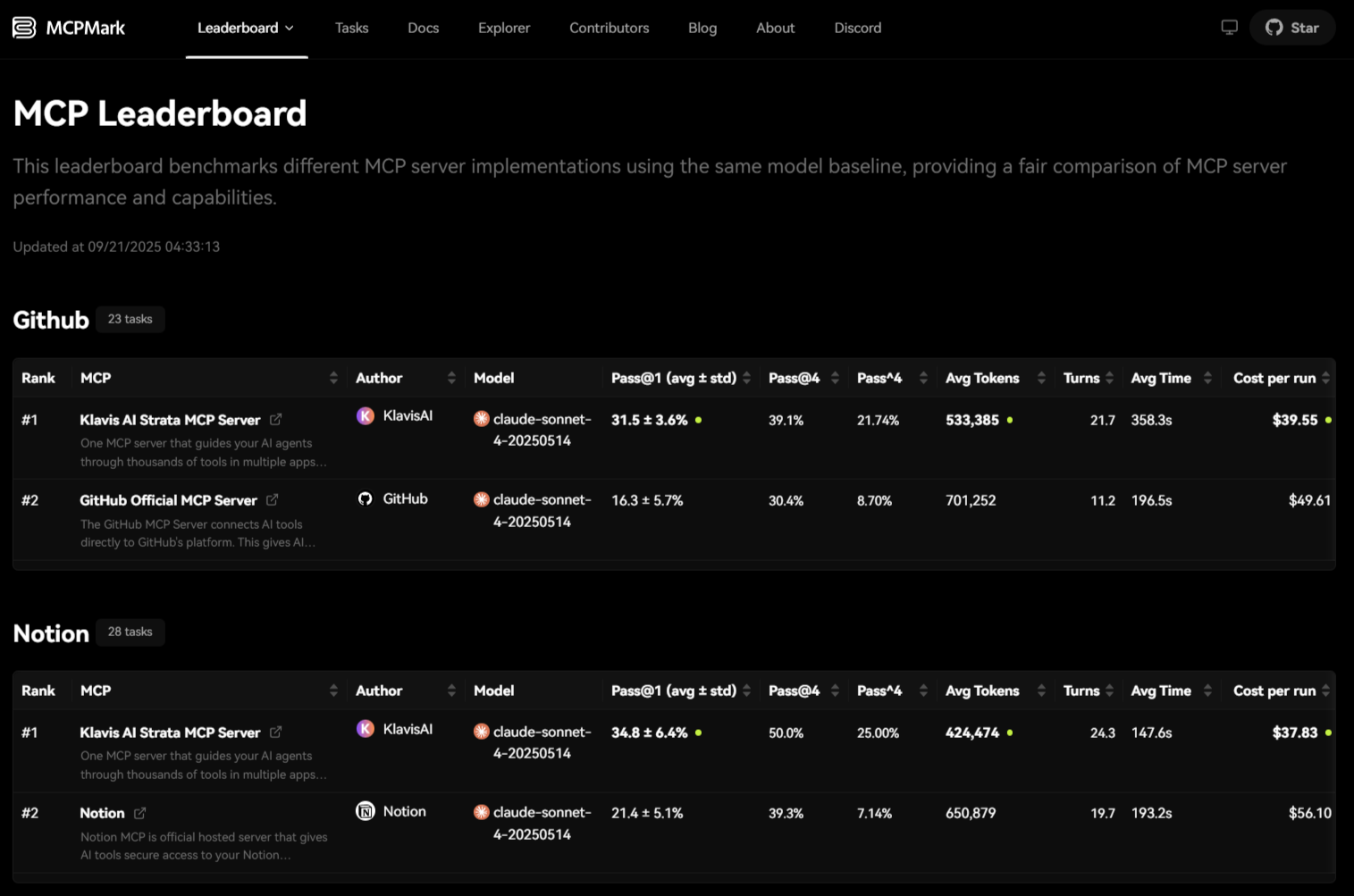
These results are striking: Klavis AI's Strata MCP Server significantly outperforms the official implementations from both GitHub and Notion—achieving nearly 2x the success rate on GitHub tasks and 1.6x better on Notion tasks, while also being more cost-effective.
The key innovation? Strata's progressive discovery approach guides AI agents through thousands of tools step-by-step rather than overwhelming them with everything at once. This architectural choice translates directly into better task completion rates and lower costs.
Frequently Asked Questions
What's the difference between function calling and tool use?
They're essentially the same thing. "Function calling" and "tool use" both refer to an LLM's ability to invoke external functions, APIs, or user-defined tools in response to user queries. Some organizations prefer "tool calling," but the capability being evaluated is identical.
Which model should I choose for my function calling application?
It depends on your specific requirements:
- Best overall performance: GPT-5 (52.56% MCPMark pass@1)
- Best cost-efficiency: Qwen-3-Coder ($36.46 per run)
- Best reasoning depth: Claude Opus 4.1 (premium tier)
- Best for Google ecosystem: Gemini 2.5 Pro
Match the benchmark to your application type and calculate cost-per-successful-task for your specific workflow.
Why do models perform so much worse on MCPMark than BFCL?
Existing MCP benchmarks remain narrow in scope: they focus on read-heavy tasks or tasks with limited interaction depth, and fail to capture the complexity and realism of real-world workflows. MCPMark specifically includes more challenging CRUD operations, longer task sequences (averaging 16.2 execution turns), and realistic initial states that make tasks significantly harder.
Should I use a larger general-purpose model or a specialized model?
The data suggests specialization matters significantly. If you have well-defined tool sets, a specialized or fine-tuned model often outperforms and costs less than a larger general-purpose model. Consider testing both approaches for your specific use case.
How important is multi-turn performance vs single-turn?
Critically important for production. While state-of-the-art LLMs excel at single-turn calls, memory, dynamic decision-making, and long-horizon reasoning remain open challenges. Most real applications involve multi-turn interactions where context management determines success or failure. Always test on multi-turn scenarios that match your actual workflows.
What role does cost play in model selection for agents?
Cost should be a primary consideration, not an afterthought. When agents make 16+ function calls per task, small per-token differences compound dramatically. Calculate total cost including retries for failed attempts. A model with 50% higher accuracy but 10x higher cost per token might actually cost more per successful task completion.