
The Model Context Protocol (MCP) has become the standard for AI agent tool connectivity, adopted by major platforms like OpenAI, Microsoft, and Google. However, it hasn't solved the core challenges of tool hallucination and exponential token costs in production AI systems.
The core problem remains: when you expose more tools to an AI agent, performance degrades. Your sales AI agent might struggle with simple tasks like "get all leads" while burning through expensive tokens processing irrelevant tool descriptions. This is where the "Less is More" principle becomes crucial for MCP design — minimizing context window usage while maximizing relevant information delivery.
The Problem
When designing tools for AI agents, context window space is your most valuable resource. Every tool you expose requires:
- A descriptive name and purpose statement
- A detailed schema of all parameters (required and optional)
- Examples and usage constraints
- Error handling documentation
To illustrate this, we prompted Cursor and Claude Code: "list all the tools you have access to, write them to a file named tools.md". As of today (Oct 12, 2025), they already expose 18 and 15 tools respectively to their coding AI agents (see the tools comparison), and these tool definitions already consume 5-7% of your context window before you even write your first prompt.
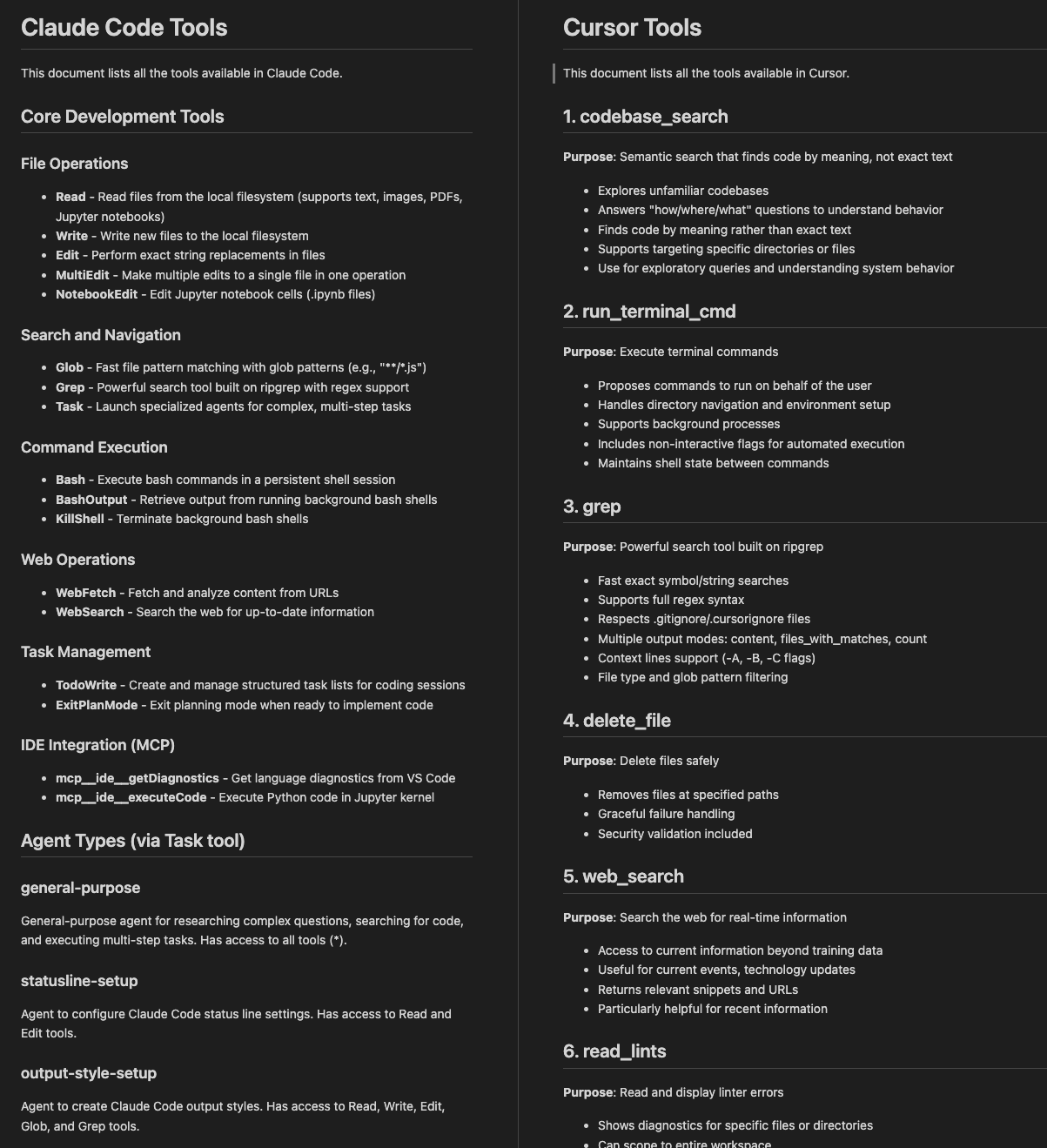
* Cursor and Claude Code already expose 18 and 15 tools to AI agents.
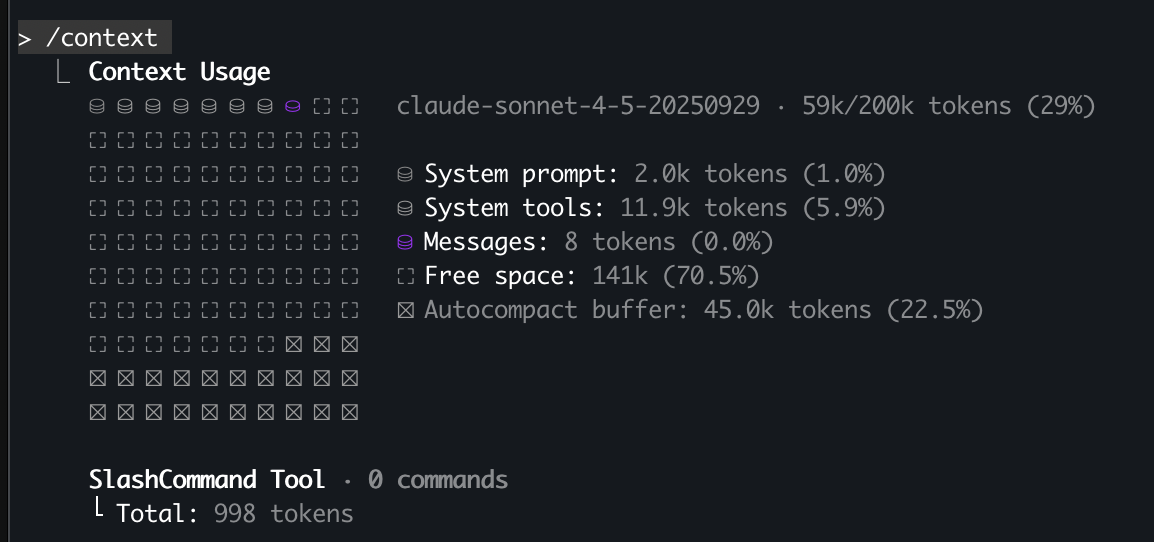
* Tool definitions consume 5.9% of context window before any user prompt in Claude Code.
The Solution
1. Semantic Search
The most straightforward approach involves building a semantic search layer on top of your tool catalog. Instead of exposing all tools upfront, the system dynamically retrieves relevant tools based on the user's query using vector similarity search.
Implementation Example:
class SemanticToolRouter:
def __init__(self, tools: List[Dict[str, Any]]):
self.model = SentenceTransformer('all-MiniLM-L6-v2')
self.tools = tools
self._build_vector_index()
def search_tools(self, query: str, top_k: int = 3) -> List[Dict[str, Any]]:
"""Search for relevant tools using semantic similarity"""
query_embedding = self.model.encode([query])
scores, indices = self.index.search(query_embedding, top_k)
return [self.tools[idx] for idx in indices[0]]
Moreover, you can indexing all avaliable tools in a vector/graph database for fast retrieval or build RAG systemon top of it.
Pros:
- Easy to implement and optimize, scales well with large tool catalogs
- Leverages existing vector database infrastructure, can incorporate user feedback to improve relevance
Cons:
- Search quality becomes a bottleneck, semantic search is notoriously difficult to perfect
- May miss relevant tools due to embedding limitations and requires continuous tuning and evaluation
When to use: Best for scenarios with large number of tools where tools have distinct, well-defined purposes.
2. Workflow-Based Design
This approach, championed by teams at Vercel and Speakeasy, focuses on building tools around complete user goals rather than individual API capabilities. Instead of exposing multiple granular tools, create single atomic operations that handle entire workflows internally.
Traditional API-Shaped Approach:
# Multiple tools requiring orchestration
create_project(name, repo)
add_environment_variables(project_id, variables)
create_deployment(project_id, branch)
add_domain(project_id, domain)
Workflow-Based Alternative:
# Single atomic operation
deploy_project(repo_url, domain, environment_variables, branch="main")
The workflow-based tool handles the complete process internally and returns conversational updates instead of technical status codes. As Vercel's engineering team notes: "Think of MCP tools as tailored toolkits that help an AI achieve a particular task, not as API mirrors".
Pros:
- Significantly reduces token usage and call overhead, easier for models to understand and use correctly
- More reliable execution with fewer failure points, better user experience with conversational responses
Cons:
- Requires predefined workflow analysis
- Not suitable for exploratory or highly customizable operations
When to use: Perfect for well-defined, repeated workflows with predictable steps. Ideal for production tools serving specific use cases.
3. Code Mode
Cloudflare recently introduced "Code Mode" as a paradigm shift in how AI agents interact with tools. Instead of sequential tool calls, agents write complete programs that use available APIs, which then execute in secure sandboxes.
Teams deploying similar concepts have reported significant improvements. For example, with CRM tools where AI made 50+ sequential calls to fetch_leads with pagination, resulting in 200K+ tokens consumed, multiple conversation rounds leading to hallucination, and degraded user experience with slow responses.
Code Mode Solution with MCP:
Instead of exposing individual fetch_leads, fetch_opportunity, etc. tools, teams have exposed a single execute_code tool:
{
"name": "execute_code",
"description": "Execute Python code in a secure sandbox with access to pre-authenticated API clients. Use for data processing, batch operations, and complex workflows. Results are automatically saved to S3 for large datasets.",
"input_schema": {
"type": "object",
"properties": {
"code": {
"type": "string",
"description": "Python code to execute."
},
"timeout": {
"type": "integer",
"default": 300,
"description": "Execution timeout in seconds"
}
},
"required": ["code"]
}
}
The LLM generates code and invokes the execute_code tool to run it in the secure sandbox:
# Code generated by LLM and passed to execute_code tool
from concurrent.futures import ThreadPoolExecutor
import json
def fetch_page(page_num):
"""Fetch a single page of leads"""
return salesforce_client.fetch_leads(page=page_num, limit=1000)
all_leads = []
page = 1
initial_batch = fetch_page(1)
total_count = initial_batch['total_count']
total_pages = (total_count + 999) // 1000 # ceiling division
# Parallel fetch pages
with ThreadPoolExecutor(max_workers=10) as executor:
futures = [executor.submit(fetch_page, i) for i in range(1, total_pages + 1)]
for future in futures:
all_leads.extend(future.result()['leads'])
# Save to S3
s3_url = s3_client.upload(
data=json.dumps(all_leads),
filename=f"salesforce_leads_{len(all_leads)}_records.json"
)
return {
"status": "success",
"total_leads": len(all_leads),
"s3_url": s3_url,
"message": f"Exported {len(all_leads)} leads to S3"
}
Moreover, you can add like Context7 as build-in tool in prompt to make sure the code written by LLM is most up to date.
Pros:
- Extremely powerful and flexible, handles complex data operations and reduces token usage for data-heavy operations
- LLMs are good at writing code than tool use
Cons:
- Security concerns (code execution, especially write operations)
- May use more tokens for simple operations
- Debugging failures is harder than with structured tool calls
When to use: Best for data processing, batch operations, complex workflows with many steps, or scenarios where the output is primarily for the user (not the LLM) to consume.
4. Progressive Discovery
This approach fundamentally changes how AI agents discover and access tools by guiding them through a logical discovery process—much like how a human would approach an unfamiliar system. This is the approach built into Strata from Klavis AI.
When an AI agent needs to accomplish a task, it works through below intelligent stages:
discover_server_categories_or_actions: Based on user intent, the agent identifies which services are relevant (e.g., GitHub for code, Slack for messaging) and receives their categories (e.g., Repos, Issues, PRs for GitHub; Channels, Messages for Slack)
get_category_actions: The agent selects relevant categories and receives available action names and descriptions, but not full schemas yet!
get_action_details: Only when the agent selects a specific action does it receive the complete parameter schema
execute_action: The agent performs the actual operation with validated parameters Additional Support Tools:
Strata also includes helper tools like documentation search and authentication handling. Evaluation against official MCP servers showed significant improvements with human evaluation of results across multi-app workflows.
Pros:
- Scales to any number of tools without context overflow, dramatically reduces initial token usage, reduces decision paralysis and hallucination.
- Works seamlessly with any external MCP server (official, community, or custom implementations)
- Leverages model's natural reasoning abilities rather than searching.
Cons:
- Adds slight latency compared to direct tool access.
- For simple operations that can be done with a single tool call, it may not be worth the overhead.
When to use: Essential for platforms with large number of tools, multi-app workflows, or when building AI agents that need access to diverse capabilities without knowing exactly what users will request. Particularly valuable for B2B SaaS platforms where different customers have different integrations enabled.
Key Takeaways
The "Less is More" principle isn't about limiting what AI agents can do, it's about strategically managing context to maximize what they can do reliably.