
When your production systems fail at 2 AM, every second counts. Companies lose an average of $5,600 every minute when IT systems go down, and roughly 91% of companies face at least one major incident each year. The difference between a minor disruption and a business-critical outage often comes down to how quickly your team can diagnose and resolve the issue.
In this guide, we'll explore how AI application developers can build intelligent, automated incident response systems that dramatically reduce Mean Time to Resolution while freeing engineers to focus on strategic work instead of repetitive firefighting.
Why Integrate PagerDuty with LLMs?
The Current State of Incident Management
With the complexity and scale of today's tech systems and infrastructure, it is nearly impossible for any one human to understand the full picture. Engineering teams face several critical challenges:
- Alert Fatigue: Teams receive hundreds or thousands of alerts daily, making it difficult to identify critical issues
- Context Switching: Teams waste time jumping between different tools, losing important details, and struggling to coordinate their response
- Knowledge Silos: Critical incident response knowledge is scattered across runbooks, documentation, and team members' heads
- Manual Triage: Manual diagnosis results in redundant assignments and extended Time to Mitigate (TTM)
How LLMs Transform Incident Response
Meta used LLMs to root cause incidents, meaning that the mean time to resolution can potentially be reduced from hours to seconds. Beyond just speed improvements, LLM-powered incident management offers:
Intelligent Root Cause Analysis: LLMs can quickly suggest probable causes of incidents by processing logs and metrics, correlating error patterns with code changes, system metrics, and historical incident data.
Automated Remediation: Large language models can streamline incident management by implementing predefined response actions automatically, such as initiating corrective scripts or protocols without human intervention.
Natural Language Interaction: Instead of navigating complex dashboards, engineers can query incident status, get summaries, and trigger actions using natural language commands.
Continuous Learning: Large language models can iteratively learn from past incidents and refine incident categories to adapt to emerging threats and trends.
More than 70% of on-call engineers gave a rating of 3 out of 5 or better for the usefulness of LLM-generated recommendations in a real-time production setting, demonstrating practical value in live environments.
Understanding Model Context Protocol for PagerDuty Integration
What is MCP and Why Does It Matter?
The Model Context Protocol is an open standard, open-source framework introduced by Anthropic in November 2024 to standardize the way artificial intelligence systems like large language models integrate and share data with external tools, systems, and data sources.
Why MCP is Perfect for Incident Management
MCP standardizes the integration of data and tools with AI Agents, which is proving incredibly valuable for building AI applications faster. For incident management specifically, MCP enables:
- Secure, Two-Way Communication: AI agents can both query incident data and take actions like acknowledging alerts or triggering escalations
- Real-Time Context: Access to live incident data, metrics, and logs rather than stale snapshots
- Tool Composition: Combine PagerDuty with monitoring tools, cloud platforms, and communication systems in a unified workflow
- Standardized Interface: Any MCP-compatible client can work with any MCP-compatible server without custom integration work
Klavis AI: Simplifying PagerDuty-LLM Integration
While MCP provides the standard, implementing production-grade MCP servers involves significant complexity: OAuth authentication flows, API rate limiting, security considerations, multi-tenancy for team environments, and progressive disclosure of tools to prevent LLM overload. Building this infrastructure from scratch can take weeks or months of engineering time.
Klavis AI provides the complete infrastructure layer for connecting LLMs to PagerDuty through MCP, eliminating months of development work.
Key Advantages:
- Built-in OAuth Support: Klavis AI handles all the complexity of PagerDuty authentication, so you don't need to manage API tokens or refresh flows
- Hosted Infrastructure: No need to deploy and maintain your own MCP servers—Klavis AI provides secure, scalable hosting
- Progressive Discovery via Strata: Instead of overwhelming your LLM with hundreds of PagerDuty API endpoints, Klavis AI's Strata guides the AI through categories progressively, achieving 13.4% higher pass@1 rate compared to traditional approaches
- Enterprise-Grade Security: Multi-tenancy, access controls, and security guardrails built-in
- Multiple Integration Paths: Choose from Web UI, Python/TypeScript SDKs, or direct REST API access
Implementing PagerDuty-LLM Integration with Klavis AI
Prerequisites
Before you begin, you'll need:
- A Klavis AI account and API key
- PagerDuty account with API access
- Python 3.8+ or Node.js 16+ (for SDK integration)
- An LLM client (Claude, GPT-4, or any MCP-compatible client)
Implementation Methods
Klavis AI supports multiple integration pathways depending on your use case:
| Method | Best For | Setup Time | Use Case |
|---|---|---|---|
| Web UI | Quick testing, non-technical users | < 2 minutes | Connecting Claude Desktop to PagerDuty |
| Python/TypeScript SDK | Custom applications, AI agents | 5-10 minutes | Building automated incident response bots |
| REST API | Language-agnostic, microservices | 10-15 minutes | Integrating with existing infrastructure |
| Open Source | Self-hosting, maximum control | days or weeks | On-premise deployments |
One click Web UI Setup
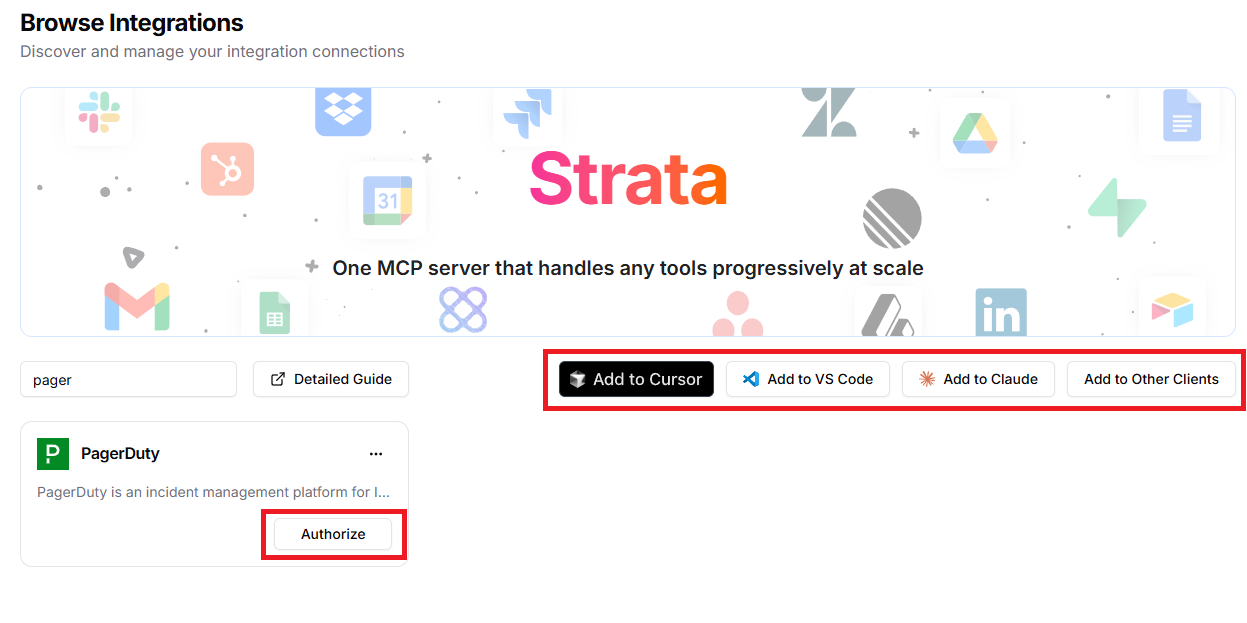
Login to Klavis AI and select "PagerDuty" from the list of available integrations, and follow the prompts to authorize access to your PagerDuty account. Then, add them to the MCP client of your choice. Detailed guide can be found in our Web UI documentation.
Quick Start: Python SDK Integration
Here's how to set up a PagerDuty MCP server using Klavis AI's Python SDK:
from klavis import Klavis
from klavis.types import McpServerName
# Initialize Klavis client
klavis_client = Klavis(api_key="YOUR_API_KEY")
# Create a Strata MCP server with PagerDuty
response = klavis_client.mcp_server.create_strata_server(
servers=[McpServerName.PAGERDUTY],
user_id="user123"
)
# Get the OAuth URL for authentication
pagerduty_oauth_url = response.oauth_urls[McpServerName.PAGERDUTY]
# Your MCP server URL is ready to use
mcp_server_url = response.server_url
Once your MCP server is created, open the OAuth URL to authorize Klavis AI to access your PagerDuty account. After authentication completes, your MCP server is fully operational and ready to connect with any MCP-compatible LLM client. Detailed documentation is available here. There are also detailed examples for connecting to different frameworks.
Real-World Use Cases for PagerDuty-LLM Integration
1. Automatic Incident Enrichment and Context Gathering
The Scenario: When a new incident fires in PagerDuty at 3 AM—"Database connection pool exhausted"—your on-call engineer wakes up with zero context. They need to check: recent deployments, similar past incidents, affected services, current system metrics, and relevant runbooks. This typically takes 10-15 minutes of frantic searching across multiple tools.
The LLM Solution: The moment PagerDuty creates the incident, your AI agent automatically:
- Queries your deployment system for any changes in the last 2 hours
- Searches PagerDuty history for similar "connection pool" incidents and their resolutions
- Checks which services depend on this database
- Pulls the relevant runbook from your documentation
- Adds all this context as a note directly in the PagerDuty incident
The Result: Your engineer wakes up to a PagerDuty incident that already contains:
🤖 Auto-Generated Context:
Recent Changes:
- api-service v2.3.1 deployed 45 minutes ago (increased connection timeout from 30s to 60s)
Similar Incidents:
- INC-8472 (2 weeks ago): Same error, resolved by restarting connection pool
- INC-7231 (1 month ago): Fixed by increasing max_connections from 100 to 150
Affected Services: payments-api, user-service, notification-worker
Runbook: docs.company.com/runbooks/database-connection-pool
Suggested Action: Recent deployment may have introduced connection leak.
Consider rolling back api-service to v2.3.0 or restarting connection pool.
2. Conversational Incident Investigation
The Scenario: During an active incident, your engineers need to quickly find information: "Which incidents affected the payments service last week?" or "Show me all P0 incidents that took longer than 2 hours to resolve." Instead of clicking through PagerDuty's UI and building complex filters, they're stuck with slow, manual searches.
The LLM Solution: Engineers can ask questions in plain English directly in Slack or their incident channel, and get instant answers:
Engineer: "Show me all database incidents from last month"
AI Agent:
Found 12 database incidents in October 2025:
P0 Incidents (2):
- INC-9823: PostgreSQL primary down (Oct 15, 2h 34m to resolve)
- INC-9647: Connection pool exhausted (Oct 8, 45m to resolve)
P1 Incidents (5):
- INC-9891: Slow query performance (Oct 28, 1h 12m)
- INC-9834: Replica lag spike (Oct 19, 38m)
...
Average resolution time: 52 minutes
Most common cause: Connection pool issues (4 incidents)
Engineer: "What did we do to fix INC-9823?"
AI Agent:
INC-9823 Resolution (Oct 15, 2025):
Root Cause: Primary database server ran out of disk space
Actions Taken:
1. Failed over to replica server (5 minutes)
2. Cleared old WAL logs on primary (15 minutes)
3. Increased disk space from 500GB to 1TB
4. Added disk space monitoring alert
Resolved by: @sarah-ops and @mike-dba
Total duration: 2h 34m
The Result: Engineers get instant answers without leaving their workflow. No more context switching to PagerDuty's web UI during critical incidents. Response time for information retrieval drops from 5-10 minutes to under 10 seconds.
3. Automatic Post-Incident Report Generation
The Scenario: After resolving a major incident, your team needs to write a post-mortem. This typically involves: collecting the timeline from PagerDuty, gathering what everyone did from Slack messages, pulling metrics, identifying the root cause, and writing up lessons learned. This process takes 2-4 hours of an engineer's time—time they'd rather spend preventing the next incident.
The LLM Solution: Immediately after an incident is marked as "Resolved" in PagerDuty, your AI agent automatically generates a complete post-mortem document:
# Post-Incident Report: INC-10234
## Executive Summary
On October 31, 2025 at 14:23 UTC, the payments API experienced a complete
outage lasting 47 minutes, affecting approximately 15,000 transaction
attempts. The incident was caused by a misconfigured Redis cache timeout
that caused cascading failures across payment processing services.
## Timeline
- 14:23 UTC: First alert triggered (payments-api high error rate)
- 14:25 UTC: Incident created, @john-oncall acknowledged
- 14:31 UTC: Root cause identified (Redis timeout misconfiguration)
- 14:35 UTC: Emergency fix deployed (reverted cache timeout to 5s)
- 14:45 UTC: Services recovered, error rate normalized
- 15:10 UTC: Incident resolved after monitoring period
## Impact
- Duration: 47 minutes
- Failed transactions: ~2,400 (16% of attempts)
- Customer complaints: 23 support tickets
- Revenue impact: Estimated $12,000 in lost transactions
## Root Cause
Deployment of payments-api v3.2.1 changed Redis cache timeout from 5
seconds to 30 seconds. Under high load, this caused connection pool
exhaustion and cascading failures.
## Resolution
Rolled back cache timeout configuration to previous value (5s). All
services recovered within 10 minutes of fix deployment.
## Action Items
1. [P0] Add integration tests for cache timeout behavior under load (@john-oncall, Due: Nov 7)
2. [P1] Implement circuit breakers for Redis connections (@sarah-backend, Due: Nov 14)
3. [P2] Add cache timeout to deployment checklist (@mike-sre, Due: Nov 7)
4. [P2] Review and document all timeout configurations (@team, Due: Nov 21)
## Lessons Learned
- Need better load testing for configuration changes
- Circuit breakers would have limited blast radius
- Response time was good (< 3 minutes to acknowledge)
The Result: Your engineer reviews and approves the auto-generated post-mortem in 10 minutes instead of writing it from scratch in 3 hours. The AI ensures nothing is missed and action items are clearly tracked. The team can quickly share learnings and move on to prevention work.
Best Practices for Production Deployment
1. Start with Read-Only Operations
Begin by implementing queries and analysis functions before enabling write operations. Start with safe operations like listing incidents and getting incident details. Then add low-risk actions like adding notes or acknowledging incidents. Only after building confidence should you enable high-impact operations like resolving incidents or modifying on-call schedules.
2. Implement Human-in-the-Loop for Critical Actions
For high-impact operations, require human approval. For example, when the LLM suggests resolving a P0 incident, request approval from on-call engineers before executing the action. If approval is granted, proceed with resolution. If blocked, add a note explaining why auto-resolution was prevented.
3. Maintain Comprehensive Audit Logs
Track all AI-driven actions for compliance and debugging. Log the timestamp, action type, incident ID, AI reasoning, outcome, model version, and confidence score for every automated action taken.
4. Set Up Guardrails and Rate Limiting
Prevent runaway automation by implementing maximum actions per hour, maximum escalations per day, and requiring approval for P0 incidents. Always validate that actions are safe to execute before proceeding.
5. Implement Fallback Mechanisms
Always have a manual override path. Use circuit breaker patterns so that after a certain number of failures, the system automatically fails over to manual processes and notifies on-call engineers.
Frequently Asked Questions
How do I prevent LLM hallucinations from causing incorrect incident actions?
LLM hallucinations are a valid concern in production incident management. Key safeguards include:
- Use MCP's structured interface: Unlike free-form API calls, MCP provides strongly-typed tool definitions that constrain LLM outputs to valid API calls only
- Implement confidence thresholds: Only execute actions when the LLM's confidence score exceeds your threshold (typically 0.8-0.9)
- Start with read-only operations: Build confidence with queries and analysis before enabling write operations
- Human-in-the-loop for critical actions: Require approval for high-impact operations
- Comprehensive validation: Validate all parameters before executing PagerDuty API calls
What's the cost of running LLM-powered incident management?
Cost varies based on incident volume and LLM provider, but typical economics look like this:
Klavis AI Pricing (for PagerDuty MCP server):
- Hobby tier: Free for up to 500 API calls/month (suitable for small teams)
- Pro tier: $99/month for 10,000 API calls (covers ~330 incidents with 30 API calls each)
- Team tier: $499/month for 100,000 API calls (large engineering organizations)
LLM API Costs (approximate, using GPT-4):
- Incident enrichment: $0.03-0.05 per incident
- Root cause analysis: $0.10-0.20 per incident
- Post-mortem generation: $0.15-0.30 per incident
ROI Calculation:
- Average engineer hourly cost: $100-150/hour
- Time saved per incident: 30-60 minutes
- Cost savings per incident: $50-150
- Break-even: 2-3 automated incidents per month
Most teams see 10-100x ROI within the first month of deployment.
How does Klavis AI's Strata progressive discovery work?
Traditional MCP implementations present LLMs with all available tools at once—for PagerDuty, this could be 100+ API endpoints. This "tool overload" reduces accuracy because the LLM must choose from too many options.
Klavis AI's Strata solves this with a four-stage progressive discovery:
- Intent Recognition: LLM identifies user's high-level goal ("investigate database incidents")
- Category Navigation: Strata presents relevant tool categories (incidents, services, users, schedules)
- Action Selection: Within the chosen category, show specific actions (list incidents, get incident details, update incident)
- API Execution: Reveal full API parameters only for the selected action
This approach achieves 13-15% higher success rates compared to showing all tools at once, as documented in Klavis AI's benchmarks.
Can I use this with Claude, ChatGPT, and other LLM providers?
Yes! MCP is an open standard supported by multiple LLM providers including Anthropic Claude (native MCP support), OpenAI ChatGPT, and Google Gemini. You can also use any custom LLM with MCP client libraries.
The beauty of MCP is that you write integration code once, and it works with any MCP-compatible LLM provider.